AI Chat with Retrieval-Augmented Generation
Overview
This Retrieval-Augmented Generation (RAG) Chat Application integrates Optical Character Recognition (OCR) using a microservice architecture. The system consists of a React Next.js 15 frontend, a FastAPI retriever service, Pinecone as a vector database, and Gemini 2.0 as the LLM and was implemented in Typescript and Python.
Videos
The videos demonstrate the functionality of Retrieval-Augmented Generation (RAG) starting with the document upload and indexing process. The demonstration highlights how extracted content is stored and retrieved, showing the impact on model responses.
Document Upload & Indexing
First we upload documents which are processed to extract and index text from readable text and images via OCR. The extracted content is converted into vector embeddings and stored in Pinecone for efficient retrieval.
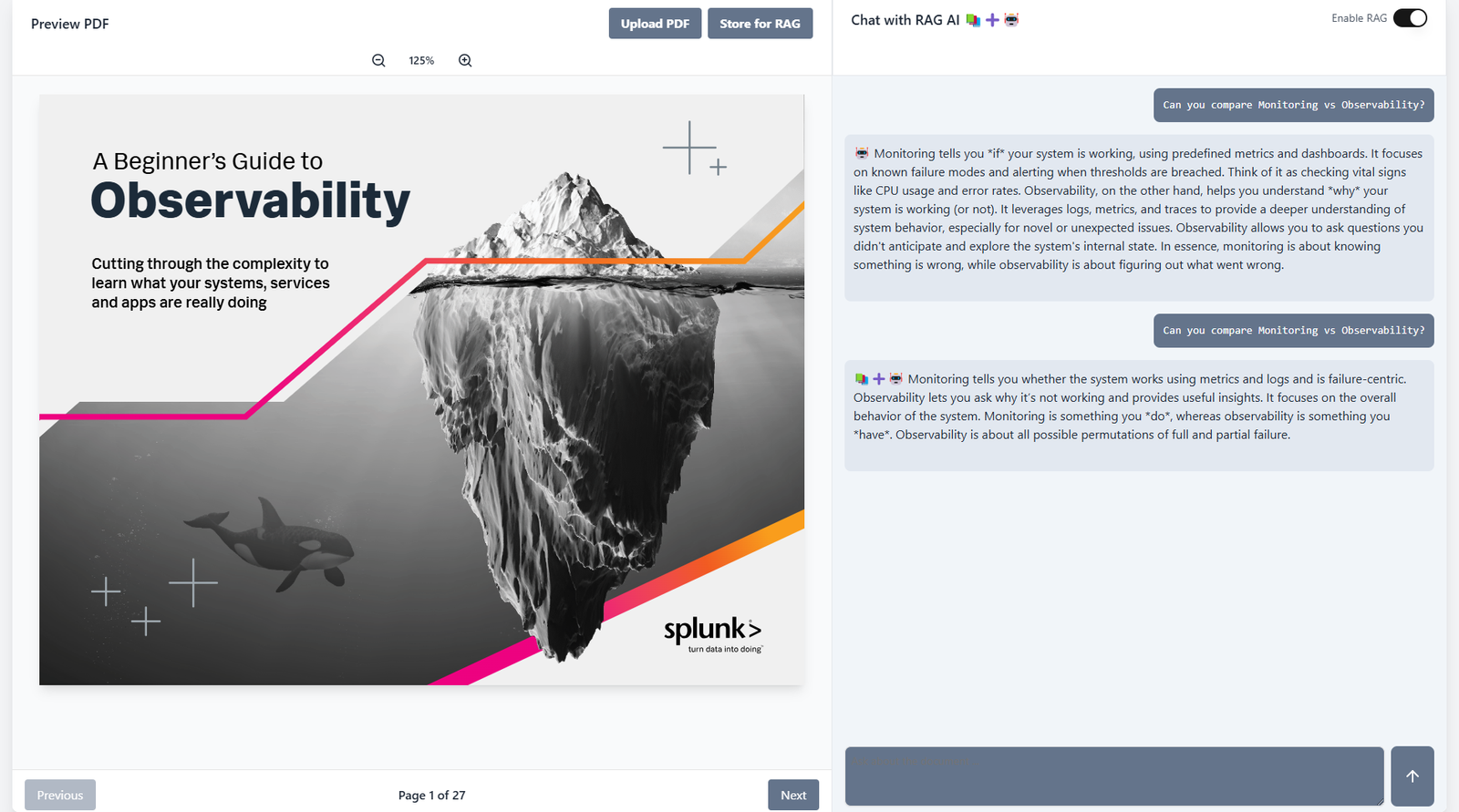
RAG vs. Non-RAG Model Responses
The video contrasts model responses with and without RAG augmentation. Without RAG, the model relies solely on its pre-trained knowledge, probably outdated and potentially leading to hallucinations or incomplete responses. When RAG is enabled, the model retrieves relevant context from indexed documents before generating an answer, controlling and improving the quality of the answer.
Enhancing RAG with OCR for Image-Based Documents
Often, documents include images with valuable information or, as shown in the example video, consist entirely of a sequence of images due to a "Print to PDF" process. These image-based documents cannot be processed through standard text extraction methods. To handle this challenge, we integrate a machine learning model for Optical Character Recognition (OCR), enabling the extraction of text from images. The extracted text is then indexed in the vector database (Pinecone) for retrieval, making the information searchable.
Architecture
-
Frontend (Next.js 15, TypeScript, React)
- Users interact with a chat interface to send queries or upload documents (PDFs, images).
- Calls Gemini 2.0 API directly from Next.js for response generation.
- Sends document uploads to the FastAPI retriever service for OCR processing.
-
FastAPI Retriever Service
- Handles document uploads and runs an OCR machine learning model to extract text from images and PDFs.
- Converts extracted text into embeddings using a transformer-based model.
- Stores embeddings in Pinecone and retrieves relevant text for queries.
-
Vector Database (Pinecone)
- Stores semantic embeddings of extracted text.
- Performs vector similarity search to retrieve relevant information based on user queries.
-
LLM (Gemini 2.0)
- The frontend (Next.js) calls Gemini 2.0 with the retrieved relevant text as context.
- Generates accurate responses using RAG, improving factual correctness.
-
Microservice Communication
- Next.js frontend interacts with FastAPI via REST APIs for document processing.
- FastAPI retrieves relevant text from Pinecone and sends it to Next.js.
- Next.js calls Gemini 2.0, appending retrieved context to improve response accuracy.
Key Benefits
✔ Scalable & Modular – Microservice design allows independent scaling of components.
✔ Improved Accuracy – RAG reduces hallucinations by retrieving relevant context before generating responses.
✔ Efficient OCR Integration – Extracts and indexes text from images and PDFs for retrieval.
✔ Fast Semantic Search – Pinecone enables efficient vector-based information retrieval.
🚀 This architecture ensures a robust AI-powered chat experience by integrating OCR, semantic search, and generative AI!